
Созданных с помощью ИИ препринтов становится все больше
15 августа 2025 г.
Некоторые статьи созданы «бумажными фабриками» – организациями, которые создают рукописи и зарабатывают на продаже авторских прав. Другие тексты демонстрируют «галлюцинации» искусственного интеллекта – такие как ссылки на несуществующие ресурсы.
Один из подобных препринтов, «Отчет о самостоятельных экспериментах: появление генеративных интерфейсов искусственного интеллекта в сновидениях», опубликованный на сервисе препринтов PsyArXiv, занимал всего несколько страниц. Указан был единственный автор без аффилиации. Эксперимент, описанный в тексте, был достаточно странным. Вскоре после удаления на сайте был опубликован препринт с почти идентичными названием и аннотацией. Автор представился независимым исследователем из Китая без высшего образования, его единственным инструментом был смартфон.
Подобный контент стал проблемой для платформ для размещения препринта. Многие из них являются некоммерческими, проверка контента требует ресурсов и может замедлить обработку работ.
Представители платформ, к которым обратились из Nature, сообщили, что пока подозрение вызывает лишь небольшая часть поступивших материалов. Например, операторы электронного архива arXiv отклоняют примерно 2% работ из-за того, что те являются продукцией искусственного интеллекта и «бумажных фабрик». В openRxiv отклоняют более десяти таких рукописей в день.
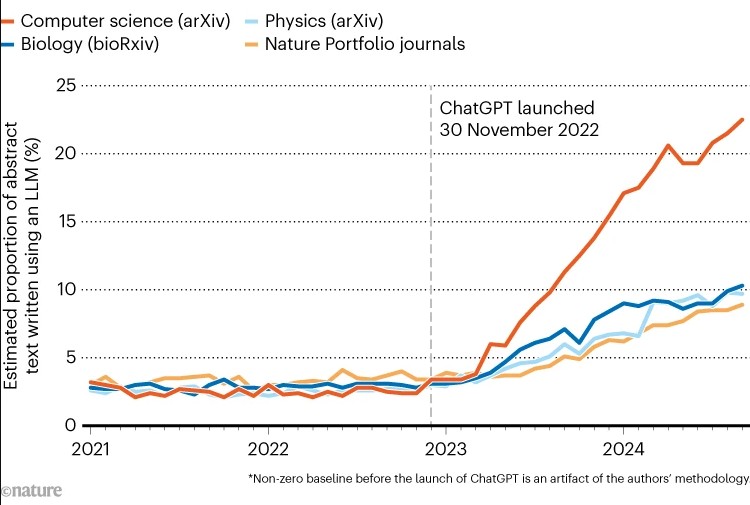
Однако количество подобных работ растет. Модераторы arXiv заметили рост числа сгенерированных работ вскоре после запуска ChatGPT в 2022 году. «Мы начали думать, что где-то в последние три месяца наступил кризис», – сообщил Стейнн Сигурдссон, научный директор arXiv. Центр открытой науки, организация, которой принадлежит PsyArXiv, опубликовал заявление о том, что «наблюдается заметный рост числа представленных работ, которые, по-видимому, были созданы или в значительной степени подготовлены с помощью инструментов искусственного интеллекта».
В исследовании, опубликованном в Nature Human Behavior, говорится, что в сентябре 2024 года большие языковые модели подготовили 22% содержания работ в сфере компьютерных наук на arXiv. Впрочем, неанглоязычные ученые могли использовать искусственный интеллект, чтобы улучшить качество письменной речи.
По словам Шахана Али Мемона, ученого из Вашингтонского университета в Сиэтле, сомнительные препринты могут распространяться быстро. «Это открывает путь дезинформации, ажиотажу... и, кроме того, [препринты] индексируются поисковой системой Google. Таким образом, люди, которые ищут в Google какую-либо информацию, могут использовать некоторые из них в качестве источников информации».
Серверы препринтов работают над улучшением ситуации. Операторы arXiv надеются ужесточить критерии для публикации статей, обобщающих литературу по определенной теме, из-за большого объема материалов крайне низкого качества, которые создаются онлайн. Центр открытой науки рассматривает ряд мер, в том числе добавление новых этапов в процессе подачи работ. Выявлением подозрительного контента занимаются как люди, так и автоматизированные инструменты. Так, Research Square использует инструмент под названием Geppetto для обнаружения признаков сгенерированного текста, сообщает Springer Nature. Команда openRxiv разрабатывает автоматизированные инструменты.
Но такие усилия – это «гонка вооружений», – говорит Ричард Север, глава openRxiv. «Мы очень обеспокоены тем, что не за горами момент, когда вы не сможете отличить полностью изготовленное от настоящего. Это вызов, с которым нам всем придется столкнуться».
Источник: Nature.